マルチバイトのサポート
Unicode は知られているすべての文字のリストです。 つまり、発声されるかどうかにかかわらず、すべての言語の文字が含まれます。 Unicode のリストには、文字ごとに一意のインデックスがあります。 最初の 128 文字は、ASCII 文字です。
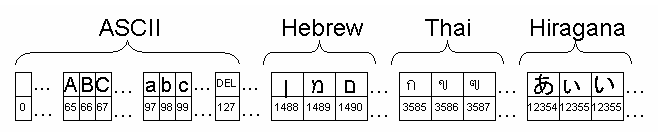
データが格納される、または計算されるときに、Unicode リストは文字を表すために使用されません。 代わりに、いわゆる文字エンコード (文字セット) が、コンピュータ上およびファイル内での文字の表現方法を定義します。 世界中では、さまざまな文字セットが使用されています。
すべての Unicode 文字をカバーする文字エンコードの中でよく使用されるものは次の 2 つです。
- UTF-8:1 文字に 1 から 4 バイトが必要です。この文字セットは、国内に限らない Web サイトやテキスト表現に広く使用されています。 Linux カーネルおよび Java では、文字列は UTF-8 でエンコードされています。
- UTF-16:1 文字に 2 または 4 バイトが必要です。このエンコードは、主として Windows NT カーネル (Win NT 以降) での文字列表現に使用されます。
ほとんどの文字セットでは、Unicode リストに含まれるすべての文字の表現が定義されているわけではありません。 実際には、世界の特定の地域で使用される文字のサブセットが定義されています。 これらは一般にコード ページ (cp) と呼ばれます。
- ASCII:シングル バイト エンコード。1 文字につき 1 バイト。
- Latin-1 (Windows コードページ 1252):シングル バイト エンコード。1 文字につき 1 バイト。
- Shift-JIS (Windows コードページ 932):ダブル バイト エンコード。1 文字につき 1 または 2 バイト。
- EUC-JP (Windows コードページ):3 つの日本語文字セットを含みます。1 文字につき 1 から 3 バイト。
Windows 用のアプリケーションを開発するときは、Unicode (UTF-16) 文字表現またはマルチバイト文字セット (MBCS) 文字表現を選択できます。 MBCS 表現は、地理的な地域に依存するコードページ エンコードを表します (日本の場合は Shift-JIS、アメリカおよび多くのヨーロッパ諸国の場合は Latin-1 など)。 すべてのデータはアプリケーションに対して選択されている同じ文字列表現で表示される必要があるので、これはすべての GUI 要素に影響します。